![Jak zachować spójność postaci przy generowaniu obrazów w AI [PORADNIK]](https://nowymarketing.pl/wp-content/uploads/2020/01/Spojnosc-obrazu-cover-photo-360x0-c-default.jpg)
Gdybyśmy zatem chcieli stworzyć serię ujęć, na których widzimy tego samego kota łapiącego mysz, uciekającego przed słoniem i gaszącego pożar, to w kolejnych odpowiedziach model generatywny zwróci nam rzecz jasna kota. Jest tylko jeden problem: za każdym razem będzie to bowiem inny kot. W dodatku często stworzony w zupełnie innej konwencji i stylistyce niż byśmy sobie tego życzyli. Opisywaną sytuację doskonale obrazuje grafika poniżej, wykonana przez narzędzie DALL·E.

Zobacz również
Sytuacja nieco się poprawi, jeśli prompt będzie bardziej szczegółowy – dokładniej opiszemy motyw główny, a w kolejnych zapytaniach manipulować będziemy jedynie interesującą nas zmienną dotyczącą akcji czy scenografii.
Poniżej przykład wygenerowany w DALL·E na podstawie tego samego promptu: („Zdjęcie hiperrelistyczne, czarny kot rasy perskiej z białymi wąsami i niebieskimi oczami [tu wstaw opis akcji] –ar 16:9”), w którym zmieniamy wybrane elementy:

Wikipedia mówi „stop” tekstom pisanym przez AI.
Teraz jest nieco lepiej.
No i kot niby ten sam. Ale gdyby mu się dobrze przyjrzeć, to jednak nie do końca sam.
Słuchaj podcastu NowyMarketing
Dzieje się tak dlatego, że modele generatywne tworzą swoje „dzieła”, korzystając w dużej mierze z przypadkowości losowanych wzorców zidentyfikowanych w treningu modelu. I nawet pisząc identyczne prompty, często będziemy rozczarowani wynikami, ponieważ model dokona własnej „interpretacji” naszych intencji. Jak zatem zredukować tą losowość i dowolność do minimum?
Jednym z rozwiązań może być edycja, którą umożliwia DALL·E lub tzw. wypełnienie generatywne – funkcja dostępna np. w programie Adobe Filefly.
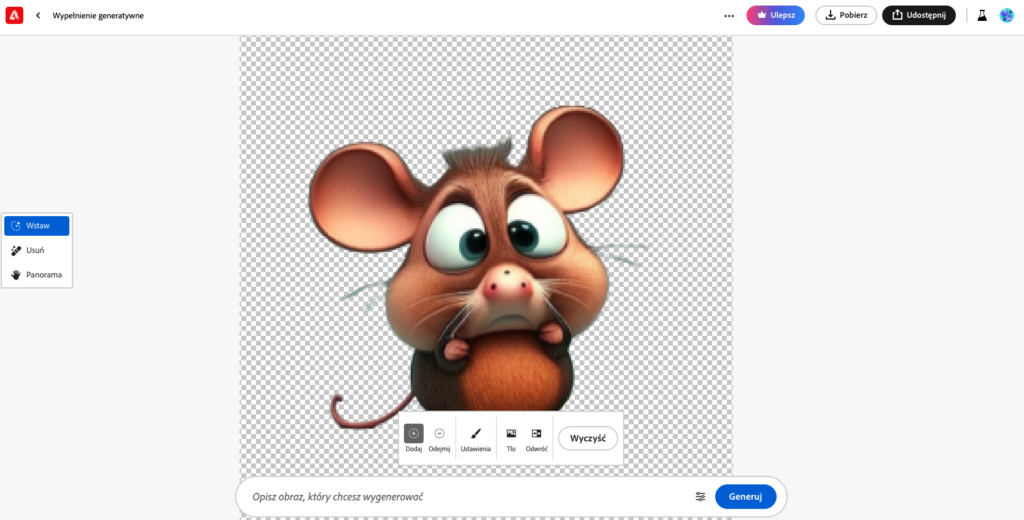
Aby tego dokonać, usuwamy tło lub wybrany element obrazu i możemy np. umieścić tę samą postać „na pustyni”, „w lesie” czy „w kosmosie”.

Będzie to jednak, jak widać, dokładnie to samo ujęcie, więc postawa i mina postaci pozostaną niezmienione. Zmienią się jedynie wybrane partie obrazu.
Podobnie sytuacja wygląda w przypadku Midjourney – jest tu co prawda dostępna opcja „Vary (Region)” umożliwiająca zaznaczenie obszaru, który ma pozostać zmodyfikowany, ale nadal nie uda się przy jej pomocy uzyskać dokładnie tego samego obiektu (lub postaci) w zupełnie różnych ujęciach.
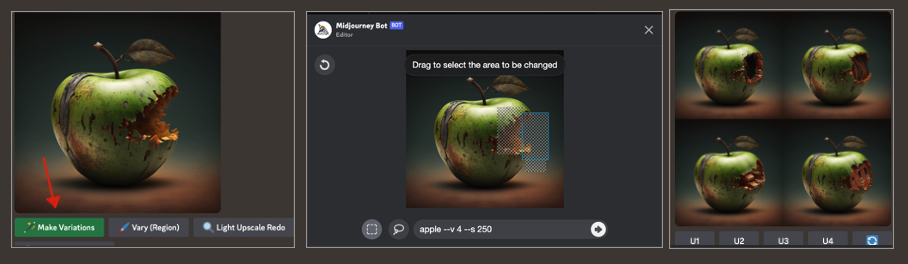
Kolejną funkcją, którą teoretycznie można by wykorzystać w Midjourney, jest mieszanie (blend) obrazów lub remix. Jednak nawet w tym przypadku otrzymywać będziemy bardzo podobne ujęcia, więc taką techniką nie zamienimy np. myszy w kapeluszu, która gra na gitarze na identyczną mysz grająca w tenisa i ubraną w sukienkę w kropki.

Innym sposobem, który również możemy wykorzystać w Midjourney, może być operowanie parametrem „seed”, który jest swoistym punktem startowym dla algorytmu pseudolosowego. „Seed” określa unikalną sekwencję, którą algorytm będzie śledził podczas generowania obrazu. Jeśli użyjemy tego samego „seeda” w procesie, to model powinien wyprodukować bardzo podobny lub niemal identyczny wynik. Takie rozwiązanie pozwala zatem na zachowanie większej kontroli nad procesem generacji.
Przy wykorzystaniu „seed”, stosując interesujące nas wymiary podobieństwa, możemy zmieniać wybrane elementy. Podobieństwo samych obrazów będzie tu faktyczne, nadal jednak będziemy mieli problem z zachowaniem identyczności postaci.

Co jeszcze możemy zatem zrobić, chcąc mieć kilka kolejnych ujęć, ale z dokładnie tym samym bohaterem spotu czy tą samą postacią wykorzystaną w animacji? Pozostaje praca u podstaw.
Innymi słowy — musimy zrobić dokładnie to, co robią np. rysownicy czy ilustratorzy tworzący postaci do filmów animowanych. Bo postać taką muszą oni przecież na samym początku zaprojektować w całości – ukazać z przodu, z tyłu, biegnącą, tańczącą czy siedzącą, w zależności od akcji i fabuły filmu.
O wykonanie dokładnie tego samego zadania możemy poprosić AI generującą obraz. Zadanie można jednak uprościć, stosując prosty trick. W przypadku DALL·E czy Midjourney możemy zastosować nawet prosty prompt w rodzaju:
„Mouse funny, one cartoon character showed in multiply angles and shots on one image”
Efekt, jaki otrzymamy, jest następujący:
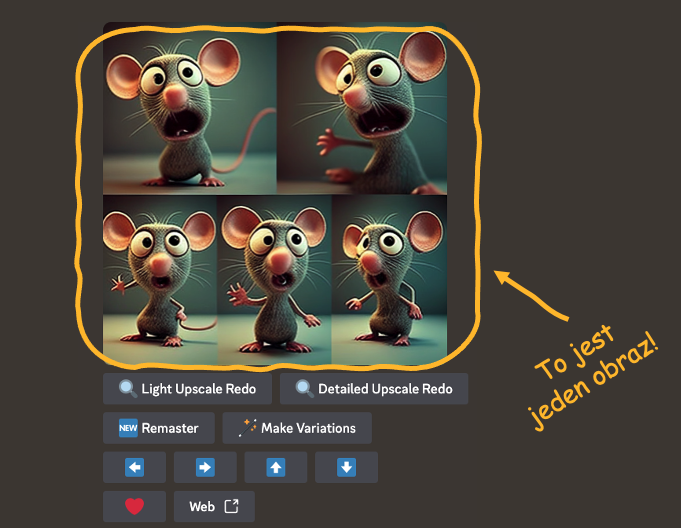
Nie musimy się więc męczyć z kolejnymi obrazkami, skoro sztuczna inteligencja może wygenerować dla nas cały arkusz podczas jednej sesji.

Można pójść o krok dalej i dookreślić w ten sposób charakter ujęć i przedstawień naszego bohatera dodając informacje kontekstowe. Jeśli więc w naszym filmiku postać kota wcielać ma się w role: strażaka, kucharza czy rycerza, to prompt może być sformułowany na zasadzie:
„A funny cartoon cat depicted from various angles and in different positions, shown as a knight, a chef, and a firefighter (e.g., jumping, running, shouting) in one image.”

Losowość modelu nie zapewni nam co prawda 100 proc. dokładności — jeden z kotów może więc mieć np. o jedną łapę za mało albo za dużo. Pomimo tych ograniczeń, jak widać na załączonym przykładzie, już po pierwszej odpowiedzi zyskujemy cały wachlarz różnorodnych możliwości.
Ten sam patent możemy zastosować także w przypadku zdjęć ludzi. Wystarczy, że zaznaczymy w prompcie elementy kontekstu, jaki interesują nas dla poszczególnych ujęć. Poniżej przykład z Midjourney wygenerowany na podstawie prompta:
„Hyperrealistic photo, the same woman, red hair, depicted in various situations, in multiple angles in different outfits and poses, as a chef, ninja warrior, firefighter.”
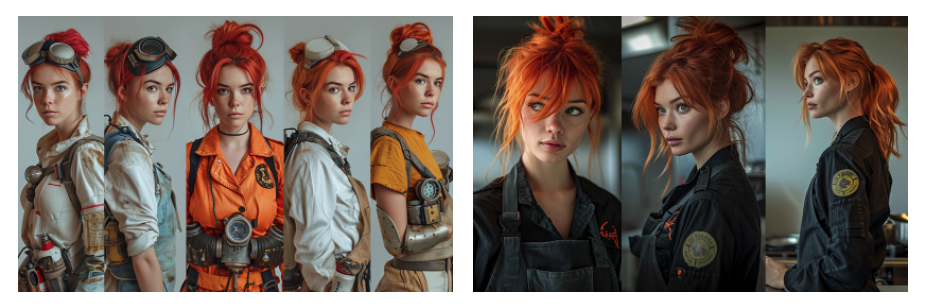
Teraz wystarczy już tylko, w dowolnym edytorze, wyciąć poszczególne ujęcia. A jeśli potrzebujemy wzbogacić je o ruch i w ten sposób je ożywić, to przerzucamy obrazki np. do PIKA, Runway czy innego modelu tworzącego filmy lub też animacje na podstawie obrazów (zob. post). Otrzymany w ten sposób materiał możemy następnie zmontować np. w programie CupCut.
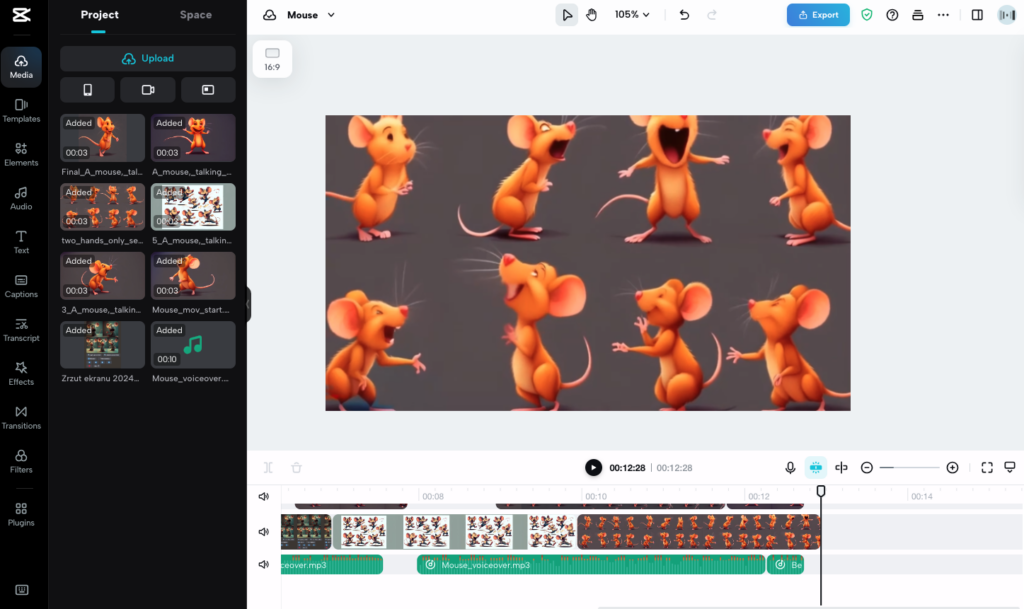
No, i gotowe.
Poniżej poskładany naprędce przykład ilustracyjny takiej animacji stworzonej opisaną wyżej metodą.
W ramach podsumowania podsuwam kilka zaleceń, czyli to, o czym zawsze warto pamiętać podczas pracy z obrazami z wykorzystaniem AI.
- Szczegółowość promptów: podstawą zachowania spójności postaci jest dokładne opisywanie motywów głównych i zmiennych scenografii. Precyzyjne prompty ograniczają losowość i pozwalają AI lepiej zrozumieć nasze zamierzenia.
- Dodawanie informacji kontekstowych do promptów: wzbogacanie promptów o szczegółowy kontekst (np. role postaci, akcje) pozwala na uzyskanie bardziej precyzyjnych i zróżnicowanych obrazów tego samego bohatera.
- Świadomość ograniczeń AI: pomimo wysokiego zaawansowania technologii, AI nie zawsze jest w stanie spełnić nasze oczekiwania, np. w kwestii dokładności detali. Należy więc być przygotowanym na pewne kompromisy.
- Eksperymentowanie i ciągłe dostosowywanie: proces tworzenia spójnych obrazów wymaga wielu eksperymentów i odmiennych podejść, aby osiągnąć optymalne rezultaty.
Miłego eksperymentowania! 🙂
Zdjęcie główne: YouTube