![Upoluj e-book „NeuroMarketing Insight” [KONKURS]](https://nowymarketing.pl/wp-content/uploads/2024/10/emoji-ikona-142x0-c-default.png)

Jakie było najbardziej inteligentne zwierzę w historii? Na pewno każdy z nas byłby w stanie przypomnieć sobie jakiegoś mądrego psa, szympansa czy delfina, którego znał osobiście bądź widział na popularnym filmiku w internecie. Jednak niewiele z tych zwierząt przejdzie do historii, tak jak pewien koń rasy kłusak orłowski o imieniu Hans.
Mądry Hans był koniem nauczyciela matematyki, Wilhelma von Ostena, który to (nauczyciel, nie koń) na fali zainteresowania umysłowością zwierząt rozpoczął eksperyment z nauczaniem swojego konia. Mądry Hans był nauczony dodawania, odejmowania, dzielenia, mnożenia, a nawet operacji na datach. Odpowiedzi na zadawane pytania udzielał wystukując wynik kopytem. A że odpowiedzi były poprawne w prawie 90%, Hans stał się atrakcją i na jego pokazy ściągały tłumy widzów.
Zobacz również
Czy Hans rzeczywiście umiał liczyć? Oczywiście nie. Czy został do tego cyrkowo wytresowany? Również nie. Badanie przeprowadzone przez psychologa Oskara Pfungsta wykazało, że Hans wyłapywał elementy nieświadomej mowy ciała osób zadających pytania i w odpowiednim momencie przestawał stukać kopytem.
Zostawmy jednak na boku prawdziwe rozwiązanie zagadki mądrości Hansa i załóżmy, że go nie znamy. Wyobraźmy sobie, że znaleźliśmy się w 1907 roku i oglądamy jego występ, zupełnie nieświadomi tego, w jaki sposób efekt został osiągnięty. „Rozmawiamy z inteligentnym koniem” – takie byłoby nasze wrażenie. I rzeczywiście, Hans był koniem bez wątpienia inteligentnym, chociaż nie w sposób, w jaki byśmy mu przypisali.
Taki właśnie zarzut pod adresem przypisywania inteligencji maszynom wysnuł amerykański filozof John Searle. Odnosząc się do koncepcji testu Turinga, w którym to obserwator zadający pytania ma ocenić, czy autorem był komputer, czy żywy człowiek, Searle podał przykład osoby zamkniętej w pokoju, do którego wrzucamy karteczki z pytaniami w języku chińskim. Jeżeli osoba ta dysponuje napisaną w swoim ojczystym języku instrukcją w jaki sposób odpisywać na konkretne zestawy chińskich znaków, to na zewnątrz pokoju będzie sprawiała wrażenie użytkownika języka chińskiego, podczas gdy sama nie będzie rozumiała ani pytań, ani odpowiedzi.
Robert Kozielski: Marketing jeszcze nigdy nie był tak pasjonujący i przerażający jednocześnie [WYWIAD]![Robert Kozielski: Marketing jeszcze nigdy nie był tak pasjonujący i przerażający jednocześnie [WYWIAD]](https://nowymarketing.pl/wp-content/uploads/2025/06/robert-kozielski-142x0-c-default.jpg)
Właśnie tak działają komputery – operują na syntaktyce (czyli sekwencjach znaków), a nie na semantyce, czyli rozumieniu znaczenia. Komputer nie rozumie opowiadanej historii, „rozumie” natomiast w jakiej kolejności ustawić konkretny zestaw znaków (output), jeżeli odbierze inny zestaw znaków (input). Pod znakiem może kryć się cokolwiek, dlatego algorytmy używane w jednej dziedzinie (np. do modelowania języka naturalnego, których efekty znamy wszyscy z wyszukiwarek internetowych) co do zasady są bardzo podobne do algorytmów, które wykrywają prawdopodobieństwa w innych dziedzinach.
Słuchaj podcastu NowyMarketing
Narracyjne modelowanie rzeczywistości
To, na czym operuje ludzki umysł, to właśnie historie, opowieści, mity. Opowiadamy rzeczy, które już się wydarzyły, co tworzy połączenia pomiędzy zdarzeniami – zazwyczaj wiemy, że nie są to połączenia konieczne, ale mimo to lubimy je tworzyć i o nich słuchać. Ilu z nas miało do czynienia z sytuacją, w której znajomi na wieść o ciężkiej chorobie, utracie pracy czy bankructwie firmy pocieszali nas anegdotą o tym, jak to ktoś im znany znalazł się w podobnej sytuacji i wyszedł z tego cało? Na racjonalnym poziomie wiemy, że rzeczywistość w ten sposób nie działa, ale tego typu opowieści pozwalają nam znaleźć sens.
Sens to pewien model rzeczywistości, według którego działamy. Obejmuje zarówno „wielkie sensy” – jak „skąd przyszliśmy, po co tu jesteśmy i dokąd zmierzamy” – ale również „sensy małe”, które tworzymy na swój codzienny użytek. Dlaczego pracuję w firmie X? Gdzie widzę się za pięć lat? Dlaczego powinienem zarabiać więcej? I to właśnie te małe sensy grają kluczową rolę w naszej interpretacji rzeczywistości, bo pozwalają również zrozumieć zachowania innych.
Ta ostatnia rzecz jest tutaj bardzo ważna. Nasz umysł jest osadzony (embedded) w rzeczywistości społecznej, co oznacza między innymi to, że musimy codziennie interpretować zachowania innych ludzi. Musimy, to znaczy nie możemy się bez tego obejść – dlatego tak często zdarza się, że nadinterpretujemy znaczenie zachowań innych, podczas gdy tak naprawdę nie posiadają one tego znaczenia. „Nie dostałem tej pracy, bo X”. „Szef był dla mnie niemiły, bo Y”. To również są opowieści i one również odpowiednio modelują nasze życie.
W marketingu najbardziej popularne jest wykorzystywanie opowieści do tłumaczenia zachowań konsumentów – obecnych i przyszłych – przez wykorzystanie modelu buyer persona. „Nasi klienci są tacy a tacy, i stąd bierze się motyw do kupna naszego produktu”. I chociaż czasem faktycznie wszystko mogłoby wskazywać, że jest tak, jak nam się wydaje, to nie możemy wykluczać, że nasze opowieści o motywach klienta są zwykłą nadinterpretacją i będą po prostu nieskuteczne.
Kto mówi prawdę, a kto blefuje
Od momentu „rewolucji big data”, która umożliwiła zbieranie i analizowanie dużych zbiorów danych, możemy własne hipotezy na temat tego „jak naprawdę jest” przetestować w ekspresowym tempie. Dotyczy to również tego, co wiemy o własnych klientach i motywach stojących za ich wyborami zakupowymi.
Różnice pomiędzy matematycznym modelem naukowym a opowieścią są znaczne. Po pierwsze, modele matematyczne są zazwyczaj probabilistyczne, podczas gdy opowieści oparte są na wynikaniu przyczynowym. Ludzki umysł nie potrafi myśleć probabilistycznie i stąd właśnie wynika potrzeba sensu. Po drugie, modele matematyczne są w stanie przekalkulować znacznie więcej parametrów niż ludzki umysł, nie upraszczając zachodzących pomiędzy zdarzeniami połączeń.
Modele matematyczne można również łatwo zautomatyzować. Big data i oparte na dużych zbiorach danych uczenie maszynowe korzystają właśnie z bogactwa zastosowań modeli matematycznych. Jest jednak fundamentalna różnica pomiędzy tworzeniem modeli matematycznych przez ludzi, a wykorzystaniem ich przez automaty: modele, tak jak opowieści, tworzą ludzie, z nastawieniem na pewne uporządkowanie świata i jego zrozumienie. Uczenie maszynowe nie ma za zadanie zrozumieć świata, ale się do niego dostosować. To, czy świat jest poznawalny i ma sens, nie ma dla pracy uczącego się algorytmu najmniejszego znaczenia.
W praktyce oznacza to, że niektóre modele będą generowały wyniki, które nie zawsze będą zrozumiałe dla ludzkiego umysłu, ale w konkretnej chwili będą najbardziej skuteczne. Najbardziej widoczne jest to w przypadku analizowania działania silników rekomendacji i ich zaskakujących wyników. Rekomendacje, jakie podsuwają nam silniki Spotify, Instagrama, Facebooka, Youtube’a czy Synerise w e-commerce, nie zawsze są oczywiste na pierwszy rzut oka. Często zdarza się, że kwestionujemy ich trafność dopiero po bezwiednym kilkukrotnym skorzystaniu z nich. Skąd algorytm „wiedział” do tej pory co będzie do nas pasowało?
To jest najbardziej interesujący element sztucznej inteligencji operującej na dużych zbiorach danych: „odkrywa” ona pewne rzeczy o nas, których sami nie wiedzieliśmy. Wszyscy znamy zapewne anegdotę o ojcu nastolatki, który zadzwonił do amerykańskiej sieci Target rozzłoszczony ofertami na artykuły dla noworodków, które sieć wysłała jego córce, która sama była nieświadoma tego, że jest w ciąży. Historię tę, która miała obrazować skuteczność przewidywań algorytmów big data można włożyć między bajki. Niemniej sama możliwość wykrycia przez algorytm korelacji, która w praktyce okaże się trafna, chociaż na poziomie racjonalnym jej nie dopuszczamy, jak najbardziej istnieje – i doświadczamy tego każdego dnia.
Wielu ludzi obawia się algorytmów sztucznej inteligencji właśnie z tego powodu: że ujawnią „prawdę” o nich samych, która jest sprzeczna z ich własną opowieścią o sobie. Kiedy we własnej wizji jesteśmy osobami o wyrafinowanym smaku czy zdrowo się odżywiającymi, ale otrzymujemy reklamę śmieciowego jedzenia i z niej korzystamy – dysonans poznawczy potrafi zaboleć. Jednak nie jest tak, że algorytmy AI znają prawdę, a my żyjemy w zakłamaniu. Są to różne modele nas samych, które są skuteczne w różnych warunkach przy realizacji różnych celów. Model, na którym operował Mądry Hans, odpowiadając na pytania, nie był ani prawdziwy, ani fałszywy, ponieważ Hans – podobnie jak uczący się algorytm – nie znał różnicy pomiędzy prawdą a fałszem. Był to natomiast model skuteczny.
Marketing narracyjny w świecie danych
Jednym z możliwych zastosowań AI jest segmentacja bazująca na analizie klastrowej, w której wykorzystujemy embedding grafów do n-wymiarowej przestrzeni wektorowej. Połączenia pomiędzy wierzchołkami stają się wtedy miarami odległości, które można opisać na liczbowych osiach. Dzielenie populacji w przestrzeni odbywa się automatycznie, na bazie określonej w modelu miary bliskości – mówiąc skrótowo, klienci w każdym klastrze są bliżej siebie nawzajem, niż któregokolwiek z klientów w pozostałych klastrach.
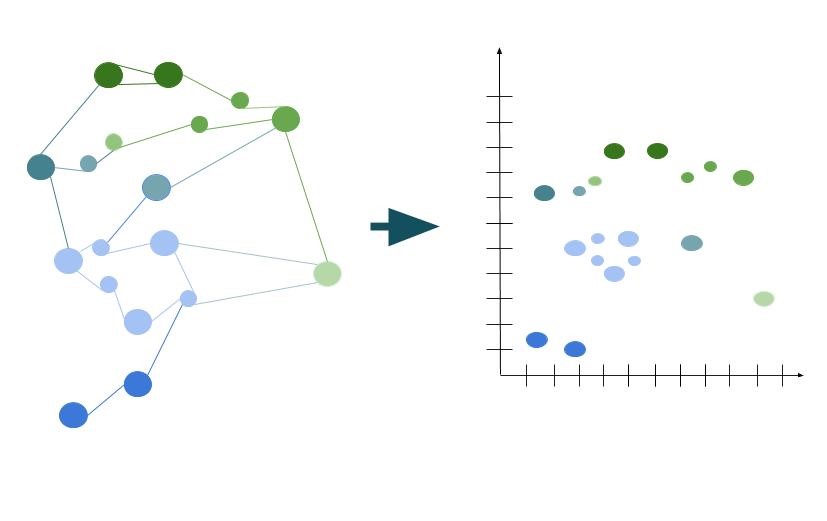
Analiza klastrowa jest doskonałym przykładem na działanie AI, ponieważ nierzadko zdarza się, że jej wynik „nie ma sensu” w kategoriach opowieści, jakie znamy z modeli buyer persona. Interpretacja klastrów jest jak najbardziej możliwa, przy sformułowaniu hipotez na temat tego, co może łączyć klientów w poszczególnych klastrach – na przykład jakie produkty kupują najchętniej w porównaniu do średniej, jak często robią zakupy, jaki dzień i jaką porę dnia preferują itd. To jednak prawie nigdy nie wyczerpie obrazu połączeń wykrytych przez model, ponieważ rzeczywistość okaże się dużo bardziej skomplikowana.
Czy w związku z tym kreowanie opowieści nie ma sensu w starciu z modelami i będzie tylko działalnością wtórną? Oczywiście nie. To, czy model będzie skuteczny, czy nie, okaże się dopiero w praktycznym zastosowaniu. Pomiędzy modelem a jego zastosowaniem jednak konieczna jest komunikacja. To tutaj wciąż pozostaje pole dla ludzkiej kreatywności, intuicji i talentu. Same dane nie odpowiedzą nam na pytania, na jakie odpowiada tworzenie historii – z czym identyfikują się nasi klienci, jakie mają potrzeby, co ich motywuje w życiu i na co mogą zwrócić uwagę w natłoku informacji napływających zewsząd. Sztuczna inteligencja nie może się z nami identyfikować, zrozumieć naszych przeżyć i tego, co nami kieruje – wciąż zostaje tutaj pole dla ludzkiej inteligencji.