
Autostrada dla Google Bot’a
Aspekty techniczne, na które najbardziej zwracamy i będziemy zwracać uwagę w przyszłym roku, to szybkość działania witryn w kontekście różnych czasów ładowania. Na potrzeby tego artykułu nazwijmy je PLT (Page Load Time).
Celem specjalistów SEO i webmasterów jest szybsze ładowanie stron i zasobów nie tylko dla użytkowników, ale także dla Google Bot’a. Jeśli strona ładuje się szybciej (czyli dostarczamy lepszą drogę), bot spędza mniej czasu na indeksowaniu, więc webmasterzy mogą zostać za to nagrodzeni.
Zobacz również
Na PLT składają się:
Time to first byte (TTFB) – czas odpowiedzi serwera od wysłania żądania do czasu przesłania pierwszego bajta informacji. To nam pokazuje, jak z perspektywy serwera (połączenia z bazą danych, przetwarzania informacji oraz systemu cache’owania danych jak i wydajność serwerów DNS) funkcjonuje dana strona. Jak sprawdzić TTFB? Najłatwiej wykorzystać jedno z takich narzędzi jak:
- Narzędzia dla Developerów w przeglądarce Chrome
- WebPageTest
- Byte Check
Jak interpretować wynik?
Funkcja „preferowanych źródeł” w wyszukiwarce Google dostępna w Polsce
Czas TTFB poniżej 100ms to zdecydowanie imponujący wynik. W rekomendacjach Google możemy znaleźć informacje o tym, że prawidłowy czas TTFB nie powinien przekraczać 200ms. Z praktyki przyjmuje się, że akceptowalny czas odpowiedzi serwera liczony do otrzymania pierwszego bajta nie może przekraczać 0,5s. Powyżej tej wartości zakładam, że mogą występować problemy na serwerze, których naprawienie wpłynie na poprawę indeksacji strony.
Słuchaj podcastu NowyMarketing
Jak poprawić TTFB?
- Przeanalizuj stronę internetową, poprawiając albo fragmenty kodu odpowiedzialne za zasobożerne zapytania do bazy (np. wielopoziomowe joiny) albo ciężki kod obciążający procesor (np. generowanie w locie skomplikowanych drzewiastych struktur danych, takich jak struktura kategorii czy przygotowywanie miniatur zdjęć przed wyświetleniem widoku bez wykorzystania mechanizmów cache’ujących).
- Wykorzystaj Content Delivery Network (CDN). Jest to wykorzystanie rozproszonych po całym świecie sieci serwerów, które udostępniają zawartość strony, taką jak pliki css, js i zdjęcia z serwerów znajdujących się najbliżej osoby, która chce wyświetlić serwis. Dzięki CDN zasoby nie są kolejkowane, jak w przypadku klasycznych serwerów i ściągają się prawie równolegle. Wdrożenie CDN powoduje skrócenie czasu TTFB nawet o 50%.
- Jeśli korzystasz z hostingu współdzielonego to rozważ migrację na serwer VPS z gwarantowanymi zasobami, jak pamięć czy moc procesora lub serwer dedykowany. Dzięki temu będziesz mieć pewność, że wpływ na działanie maszyny (lub wirtualnej maszyny w przypadku VPS) masz tylko Ty i jeśli coś działa wolno, to problemów musisz szukać po swojej stronie, a niekoniecznie w firmie zapewniającej serwer.
- Pomyśl nad wdrożeniem systemów cach’ujących. W przypadku WordPress’a masz do wyboru wiele wtyczek, których wdrożenie nie jest problematyczne, a efekty będą natychmiastowe. Do najczęściej wybieranych przeze mnie należą WP Super Cache i W3 Total Cache. Jeśli korzystasz z dedykowanych rozwiązań, to rozważ implementacje Redis, Memcache czy APC, które umożliwiają zrzucanie danych do plików lub przechowywanie ich w pamięci RAM, co ekstremalnie zwiększa wydajność działania sklepów czy stron internetowych.
- Włączenie obsługi protokołu HTTP/2 lub jeśli już serwer ma taką możliwość, HTTP/3. Zysk w postaci szybkości jest niewyobrażalny. Na serwerze testowym po wdrożeniu HTTP/2 udało mi się zmniejszyć TTFB z 500ms (przy HTTP/1) do ok 30ms (przy HTTP/3 i serwerze lightspeed).
DOM processing time. Czas pobrania całego kodu HTML. Im kod jest bardziej efektywny, tym mniej zasobów potrzeba na jego załadowanie, co wpływa na zadowolenie użytkownika, ale również spółki z Doliny Krzemowej – mniejsza ilość zasobów potrzebna na przechowywanie strony w indeksie wyszukiwarki (wskazanie dotyczące wagi tego czynnika pojawiło się w takich materiałach jak Google Insight Speed na początku tego roku jako Excessive DOM Size).
Jestem fanem zmniejszania objętości kodu HTML poprzez eliminację nadmiarowego kodu HTML oraz przerzucanie generowania wyświetlanych elementów na stronie z kodu HTML do CSS, np. przy użyciu pseudo klas :before i :after, a także wyrzucenie z HTML obrazków w formacie SVG (tych zapisanych wewnątrz znaczników <svg></svg>).
Aby jak najbardziej zmniejszyć objętość strony, rozważ usunięcie kodu JS i CSS, który występuje wewnątrz <body></body> (inline css, inline js).
Page rendering time. Wyrenderowanie strony, w tym pobrania zasobów graficznych oraz pobranie i wykonanie kodu JS.
Minifikacja i kompresja zasobów to podstawowe działanie przyspieszające czas renderowania strony. Asynchroniczne ładowanie zdjęć, minifikacja kodu HTML, migracja kodu Java Script z kodu HTML (takiego, gdzie ciała funkcji są bezpośrednio zawarte w kodzie HTML) do zewnętrznych plików Java Script ładowanych asynchronicznie według potrzeb. Takie działanie pokazuje, że dobrą praktyką jest ładowanie tylko tego kodu Javascript czy kodu CSS, który jest potrzebny na aktualnej podstronie, np. jeśli użytkownik jest na stronie produktu, to przeglądarka nie musi ładować kodu Java Script, który będzie wykorzystywany w koszyku czy w panelu zalogowanego klienta.
Im więcej zasobów jest potrzebnych do załadowania, tym Google Bot musi więcej czasu poświęcić na obsłużenie pobrania informacji o zawartości naszej strony. Jeśli przyjmiemy, że każda strona ma przyporządkowaną maksymalną ilość / maksymalny czas odwiedzin robota Google kończący się zaindeksowaniem treści, to im bardziej wykorzystamy ten czas, tym mniej stron uda się nam przesłać do indeksu wyszukiwarki.
Ostatnie zagadnienie wymaga większej uwagi. Crawl budget, bo o nim mowa, znacząco wpływa na to, w jaki sposób Google Bot podchodzi do indeksacji treści na stronie internetowej. Na potrzeby zrozumienia, jak funkcjonuje i czym jest budżet crawlowania, wprowadźmy pojęcie CBR (Crawl Budget Rank) jako ocenę przejrzystości struktury serwisu.
Jeśli często wpuszczamy bota „w maliny” i prezentujemy zduplikowane wersje tych samych treści na stronie, to nasz CBR maleje. Informacje na ten temat będziemy mogli obserwować na dwa sposoby:
Google Search Console
Analizując i oceniając problemy związane z indeksacją strony w Google Search Console będziemy mogli zaobserwować narastające problemy w zakładce Stan > Wykluczono, w takich sekcjach jak:
- Strona zeskanowana, ale jeszcze nie zindeksowana.
- Strona zawiera przekierowanie.
- Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik.
- Duplikat, użytkownik nie oznaczył strony kanonicznej.
Access Log
To najlepsze źródło informacji o tym, jak po naszej stronie porusza się Google Bot. Na podstawie danych w logu jesteśmy w stanie odtworzyć strukturę serwisu w interpretacji Google Bot’a, odnajdując słabe miejsca w naszej architekturze informacji tworzonej przez linki wewnętrzne i elementy nawigacyjne.
Do najczęstszych błędów programistycznych, wpływających na problemy z indeksacją, należą:
- Źle zbudowane mechanizmy filtrowania i sortowania danych, powodujące powstanie tysięcy zduplikowanych podstron.
- Linki typu „Szybki podgląd”, które w wersji dla użytkownika pokazują popup z danymi na warstwie, a dla Google Bota tworzą stronę z powielonymi informacjami o produkcie.
- Stronicowanie, które nigdy się nie kończy.
- Linki na stronie przekierowujące do zasobów pod nowym URL.
- Blokowanie dostępu dla robotów do często powtarzalnych zasobów.
- Klasyczne błędy 404.
Im więcej bałaganu mamy na stronie, tym bardziej nasz CBR maleje, przez co Google Bot mniej chętnie odwiedza naszą stronę (mniejsza częstotliwość), indeksuje coraz mniej treści, a w przypadku złej interpretacji właściwej wersji zasobów pozbywa się stron, które wcześniej były w indeksie wyszukiwarki.
Klasyczna koncepcja budżetu indeksowania pozwala nam zorientować się, ile stron Google Bot średnio indeksuje dziennie (na podstawie logów) w porównaniu do łącznej liczby stron w witrynie. Wyobraźmy sobie dwie sytuacje:
- Twoja witryna ma 1000 stron, a Google Bot codziennie crawluje 200 z nich. Co to nam mówi? Czy to zły czy dobry wynik?
- Twoja witryna ma 1000 stron, a Google Bot crawluje 1000 stron. Powinieneś być szczęśliwy czy zmartwiony?
Bez rozszerzenia koncepcji budżetu indeksowania o dodatkowe wskaźniki jakości interpretacje powyższych danych są bezwartościowe. Drugi przypadek może być zarówno dobrze zoptymalizowaną stroną, jak i sygnałem ogromnego problemu. Załóżmy, że Google Bot crawluje tylko 50 stron, które chcesz zaindeksować, a pozostałe (950 stron) to strony śmieciowe / powielone / think content. Mamy problem.
W swojej pracy staram się zdefiniować metrykę, taką jak CBR. Podobnie jak w przeszłości Page Rank. Im wyższy PR, tym silniejsze linki wychodzące. To im większy CBR, tym mniej problemów mamy.
Można by się pokusić o interpretacje liczbową CBR jako:
IS – ilość zaindeksowanych stron przesłanych w mapie witryny (indexed sitemap).
NIS – ilość stron przesłanych w mapie witryny (non indexed sitemap).
IPOS – ilość stron zaindeskowanych nieprzesłanych w mapie witryny (indexed pages outside sitemap).
SNI – ilość stron zeskanowanych, ale jeszcze nie zaindeksowanych.
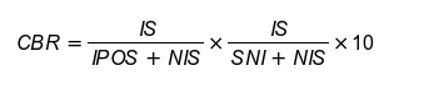
Pierwsza część równania opisuje nam stan witryny w kontekście naszego wyobrażenia tego, co chcemy, aby znajdowało się w indeksie wyszukiwarki (strony w mapie strony to z założenia te, które chcemy indeksować) vs. rzeczywistość, czyli to do czego dotarł bot Google i zaindeksował nawet jeśli tego nie chcieliśmy. W idealnym przypadku IS = NIS, a IPOS=0.
W drugiej części równania pod lupę bierzemy liczbę stron, do których dotarł Google Bot vs faktyczne pokrycie w indeksowaniu. Jak wyżej w idealnych warunkach SNI = 0.
Otrzymana wartość pomnożona przez 10 da nam liczbę większą od zera i mniejszą od 10. Im wynik bliższy 0, tym mocniej powinniśmy pracować nad CBR.
Jest to tylko moja własna interpretacja na podstawie analizy projektów, którymi zajmowałem się na przestrzeni ostatniego roku. Im bardziej udawało mi się ten współczynnik poprawiać (zwiększyć CBR), tym bardziej poprawiały się widoczność, pozycja i docelowo ruch na stronie.
Jeśli przyjmiemy, że CBR jest jednym z czynników rankingowych wpływających na ogólny ranking domeny, to ustawiłbym go jako najważniejszy czynnik onsite’owy zaraz po offsite’ owym Page Ranku (PR). Bo cóż nam po świetnych treściach, unikalnych opisach zoptymalizowanych pod wybrane pod kątem popularności słowa kluczowe, jeśli Google Bot nie będzie miał okazji wprowadzić tych informacji do indeksu wyszukiwarki?
User First Content
Na naszych oczach ma miejsce kolejna duża rewolucja w zakresie czytania i interpretowania zapytań oraz treści na stronach. Historycznie do takich przełomowych zmian należą:
- Normy ilościowe – 1000 znaków ze spacjami i 3x słowo kluczowe w treści. Do pewnego momentu był to gwarant sukcesu, pewnego dnia po prostu przestało mieć to znaczenie
- Thin content – ruch budowany na tagach naszpikowanych słowami kluczowymi. Z dnia na dzień ta strategia przestała działać, podobnie jak sztucznie generowany content niskiej jakości (mieszarki tekstów).
- Duplicate content – robot Google nauczył się (mniej lub bardziej dobrze) rozpoznawać, który tekst zaindeksowany w wyszukiwarce jest oryginalny (powstał jako pierwszy), a który jest jego kopią. W dalszej konsekwencji powstała Panda (algorytm Google), który co kilka miesięcy filtrował i flagował strony niskiej jakości oraz obniżał ich ranking i pozycje w wyszukiwarce. Obecnie działa on w trybie „na żywo”.
- Rank Brain – algorytm, który przy wykorzystaniu machine learningu interpretuje zapytania użytkowników wyszukiwarki przy mniejszym nacisku na słowa kluczowe, a większym na kontekst zapytania (w tym historię zapytań) i wyświetla bardziej dopasowane do kontekstu wyniki.
- E-A-T – eliminacja treści wprowadzających albo mogących wprowadzać w błąd ze względu na niski autorytet autora treści, a co za tym idzie domeny. Szczególnie odbiło się to na branży medycznej oraz finansowej. Artykuły, za którymi nie stoją eksperci, a będą dotyczyć powyższych sfer życia, mogą narobić wiele szkód. Stąd walka Google z domenami zawierającymi słabe merytorycznie i jakościowo treści.
Tworzenie treści pod konkretne słowa kluczowe traci na znaczeniu. Długie artykuły naszpikowane frazami sprzedażowymi przegrywają z lekkimi i wąsko tematycznymi artykułami, jeśli content zostanie zaklasyfikowany jako ten, który odpowiada intencjom użytkownika i pasujący do kontekstu wyszukiwania.
BERT (Bidirectorial Encoder Representations from Transformers), bo o nim mowa, to algorytm, który stara się zrozumieć i zinterpretować zapytanie na poziomie potrzeb i intencji użytkownika. Dla przykładu dla zapytania: „Jak długo można przebywać w USA bez ważnej wizy?” może wyświetlić zarówno wyniki stron, na których znajdziemy informacje o długości trwania wiz w zależności od kraju pochodzenia (np. dla wyszukań z Europy), jak i te mówiące o tym, co grozi osobie, której wiza wygaśnie, czy też opisujące jak zalegalizować swój pobyt w USA.
Czy da się tworzyć content idealny? Odpowiedź jest prosta – nie, ale z pewnością można sobie w tym trochę pomóc.
W procesie ulepszania treści, tak aby były bardziej dopasowane, możemy wykorzystać takie narzędzia jak:
- ahrefs.com – do budowania inspiracji contentowych na podstawie analizy konkurencji,
- senuto.com – co daje nam wyobrażenie o strategii contentowej konkurentów w serp poprzez analizę słów kluczowych, dla których strony konkurentów są w rankingu, a naszych stron brak,
- semstorm.com – do budowania i testowania longtailowych zapytań uwzględniających np. wyszukiwania w formie pytań,
- surferseo.com – do analizy porównawczej treści naszej strony ze stronami konkurencji w SERP, który ostatnio jest jednym z moich bardziej ulubionych narzędzi.
W tym ostatnim możemy przeprowadzać analizę porównawczą na poziomie słów, fraz złożonych, tagów html (np. paragrafów, pogrubień i nagłówków) wyciągając wspólne „dobre praktyki”, które możemy znaleźć na stronach konkurencji, które ściągają ruch z wyszukiwarki do siebie.
Jest to po części sztuczne optymalizowanie treści, ale w wielu przypadkach skutecznie udawało mi się podnieść ruch na stronach, których treści zmodyfikowałem, wykorzystując dane zebrane przez powyższe narzędzia.
Zawsze powtarzam, że nie ma jednego dobrego sposobu na SEO. To testy pokazują nam, czy strategia zarówno ta dotycząca budowania struktury strony, jak i samych treści okaże się dobra.
Z okazji Nowego Roku życzę Wam wysokich pozycji, konwertującego ruchu i nieustających wzrostów.

Max Cyrek
„Do not accept ‘just’ high quality. Anyone can do that. If the sky is the limit, find a higher sky”. Razem z całym zespołem Cyrek Digital pomaga firmom w cyfrowej transformacji. Specjalizuje się w technicznym SEO. Na działania marketingowe patrzy zawsze przez pryzmat biznesowy. Jest posiadaczem certyfikatu DIMAQ Professional.
Nowy Marketing jest patronem medialnym DIMAQ – międzynarodowego standardu kwalifikacji e-marketingowych. Artykuł został przygotowany przez eksperta – posiadacza certyfikatu DIMAQ Professional.